

随着自动驾驶技术的发展,多目标跟踪已成为计算机视觉领域的热点问题之一。 MOT是一项关键的视觉任务,可以解决拥挤场景中的遮挡、外观相似、小目标检测困难、ID切换等不同问题。为了应对这些挑战,研究人员尝试利用 Transformer 的注意力机制、方案卷积神经网络的轨迹、目标在不同帧中的外观到 SIAMESE 网络的外观之间的相关性,同时也尝试了 CNN基于简单的 iOU 匹配的网络,以及 CNN 网络和运动预测 LSTM。为了整合这些去中心化的技术,作者在过去三年里研究了 100 多篇论文,试图提取出近年来研究人员比较关注的解决 MOT 问题的技术。作者列出了大量的应用和可能的方向,以及MOT如何与现实生活联系起来。作者的评论试图展示研究人员使用的技术的不同观点,并为潜在的研究人员提供一些未来的方向。此外,作者还在这篇评论中收录了流行的数据集和指标。
简介
目标跟踪是计算机视觉中非常重要的任务之一。它是在目标检测后才出现的。为了完成目标跟踪任务,首先将目标定位在一帧中。然后为每个目标分配一个单独的ID。连续帧中的每个相同目标都会生成一条轨迹。这里,一个目标可以是任何类别,比如行人、车辆、体育运动中的运动员、天空中的鸟类等。如果作者想在一帧中跟踪多个目标,则称为多目标跟踪或MOT。
在过去的几年里,出现了一些关于MOT的评论[1]、[2]、[3]、[4]。但它们都有局限性。其中一些方法仅包括深度学习方法。他们只注重数据关联,只分析问题,不对论文进行分类,缺乏实际应用的介绍。
因此,综上所述,作者通过以下方式来组织本次工作:
找到 MOT 的主要挑战
列出常用的MOT方法

MOT基准数据集简介
MOT指标摘要
探索各种应用场景
MOT 的主要挑战
覆盖
当您想要看到的目标完全或部分隐藏或被同一帧中的另一个目标遮挡时,就会出现问题。大多数 MOT 方法基于没有传感器数据的相机。这就是为什么当目标相互遮挡时,跟踪器追踪目标位置有点困难的原因。此外,在拥挤的场景中,为了模拟人的交互,阻塞变得更加严重[5]。随着时间的推移,边界框定位目标的使用在 MOT 社区中非常流行。但在拥挤的场景中,[6]很难处理,因为grouptruth边界框通常相互重叠。通过结合处理目标跟踪和分割任务,可以部分解决这个问题[7]。在文献中,作者可以看到用于寻找全局属性的外观信息和图形信息来解决覆盖问题[8]、[9]、[11]、[11]。然而,频繁的阻塞对 MOT 问题的精度降低有显着影响。因此,研究人员试图在没有任何提示的情况下解决这个问题。下图中对盖子进行了说明。下图B中,红衣女子几乎被灯罩住了。这是封面的一个例子。
轻量级架构
尽管大多数问题的最新解决方案都依赖于重量级架构,但它们非常资源。因此,在MOT中,重量级架构对于实时目标跟踪非常不利。因此,轻量化架构一直受到研究者的高度重视。对于 MOT 中的轻量化结构,还有一些额外的挑战需要考虑[12]。 BIN等人提到了轻量级架构面临的三大挑战。例如,目标跟踪架构需要预训练权重以实现良好的初始化和微调跟踪数据。因为NAS算法需要来自于目标任务的指导,也需要可靠的初始化。 NAS算法需要同时关注骨干网络和特征提取,这样最终的结构才能完全适合目标跟踪任务。最终的架构需要编译紧凑、低延迟的构建模块。
其他常见挑战
MOT 架构经常受到目标检测不准确的影响。如果没有正确检测到目标,所有追踪目标的努力都将付诸东流。有时,目标检测的速度已成为 MOT 架构的主要因素。对于背景失真,目标检测有时会变得非常困难。照明在目标检测和识别中也起着至关重要的作用。因此,所有这些因素在目标跟踪中变得更加重要。由于相机或目标的运动,模糊运动使得MOT更具挑战性。很多时候,MOT架构很难判断一个目标是否是真正的输入目标。挑战之一是检测和 tracklet 之间的正确连接。在许多情况下,不正确和不准确的目标测试也是精度低的结果。也存在一些挑战,例如相似的外观常常使模型感到困惑。轨迹的开始和终止以及终止是MOT中的关键任务。多个目标之间的交互、ID切换(同一目标在连续帧中不同)。由于形状等外观特征的非刚性变形和类间相似性,在许多情况下,人和车辆带来一些额外的挑战[13]。例如,车辆的形状和颜色与人的衣服不同。最后,较小尺寸的目标可以形成各种不同的视觉元素。李廷等人。尝试用更高分辨率的图像和更高的计算复杂度来解决这个问题。他们还将分层特征图与传统的多尺度预测技术相结合[14]。
MOT法
多目标跟踪任务通常分为两个步骤:目标检测和目标关联。有的专注于目标检测,有的则与数据关联相关。有很多方法可以完成这两个步骤。无论是测试阶段还是相关阶段,这些方法都不是完全独立的。
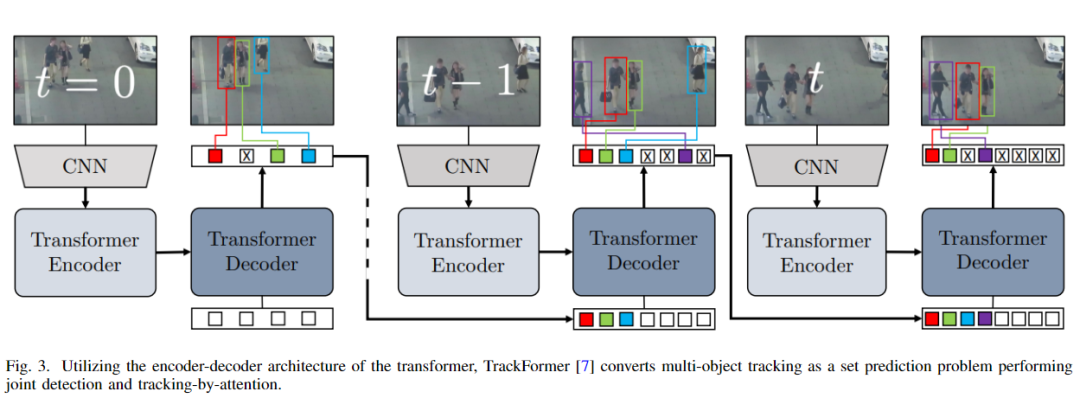
变压器
Transformer 是一种深度学习模型。与其他模型一样,它有两部分:编码器和解码器[16]。编码器捕获自注意力,解码器捕获交叉注意力。这种注意力机制有助于长期记忆上下文。根据查询键,转换器预测输出。尽管过去它仅被用作语言模型,但近年来,视觉研究人员开始关注它以利用上下文记忆。大多数情况下,在MOT中,研究人员尝试根据之前的信息预测目标来预测下一帧的下一帧。作者认为Transformer是最好的解决方案。由于Transformer专门处理序列信息,因此Transformer可以完美地完成逐帧处理。下图是Transformer的跟踪示例。
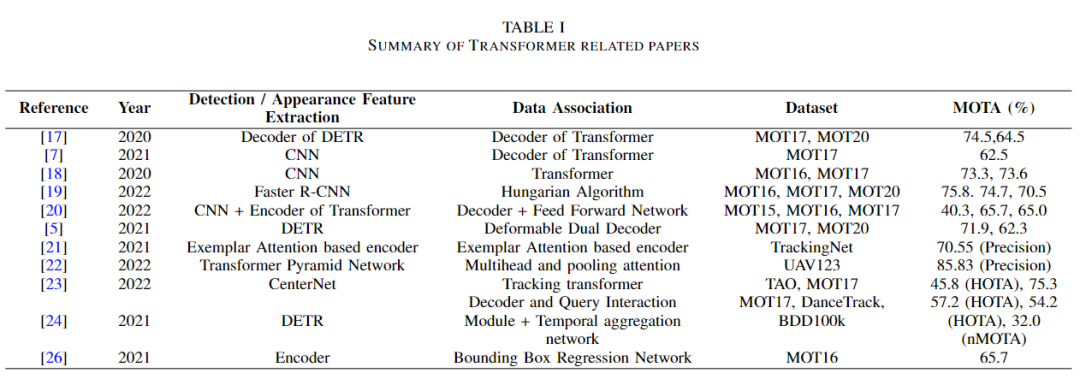
下表给出了 MOT 中基于 Transformer 方法的完整总结。
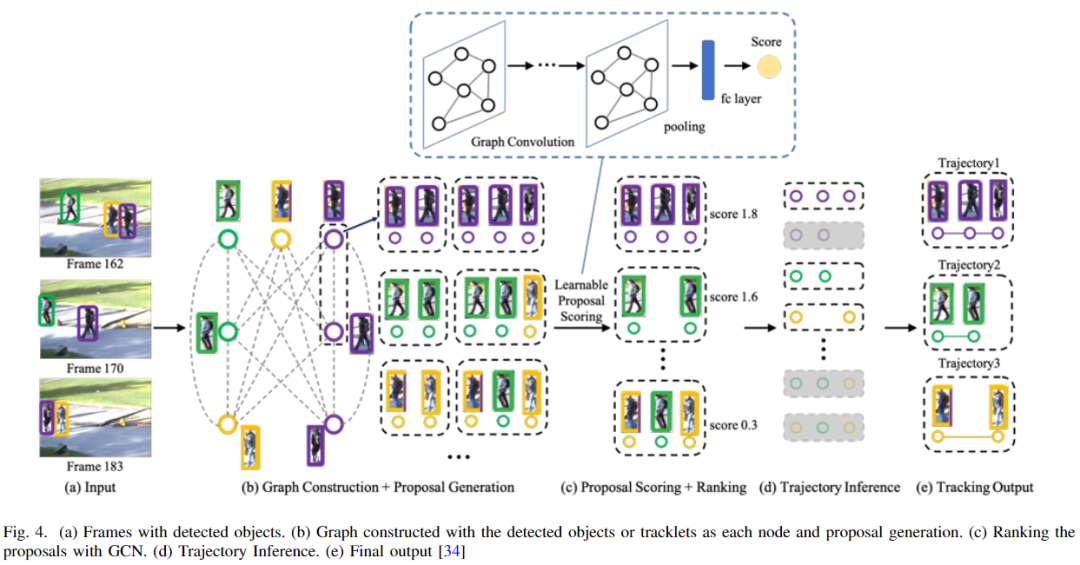
图解模型
图形卷积网络(GCN)是一种特殊的卷积网络,其中神经网络以图形形式而不是线性形式应用[27]。另外,最近的趋势是使用图模型来解决MOT问题。从连续帧中检测到的目标集被视为一个节点,两个节点之间的链接被视为一条边。一般情况下,数据关联是由匈牙利算法完成的[28]。下图展示了基于GCN的目标跟踪示例。
下表概述了图形模型的 MOT 问题。

检测和目标关联

在这种方法中,检测是通过任何深度学习模型完成的。但主要挑战是关联目标,即跟踪兴趣目标的轨迹[37]。在这方面,不同的论文遵循不同的方法。
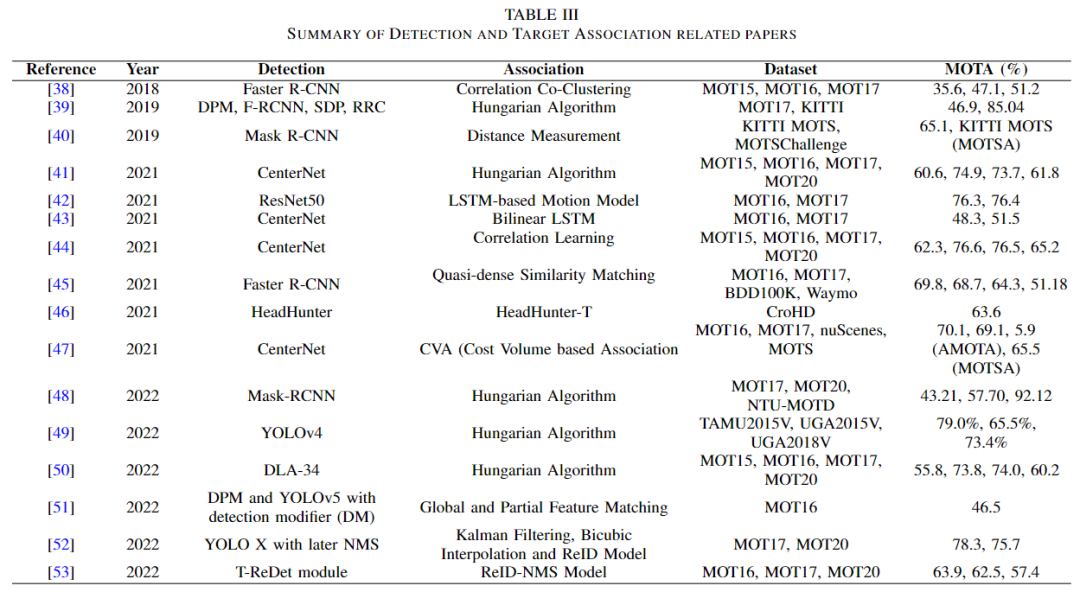
如上表所示,主要介绍了一些方案。 Margret 等人选择了自下而上的方法和自上而下的方法[38]。在底部,点轨迹被确定。但在顶部向下的方法中,边界框是确定的。然后,通过将这两者结合起来,就可以找到完整轨迹的目标。在[39]中,为了解决关联问题,Hasith等人简单地测试了他们的目标,并使用著名的匈牙利算法来关联信息。 2019年,Paul等人提出了Track-RCNN[40],它是R-CNN的扩展,这显然是MOT领域的一项革命性任务。到2022年,作者可以看到MOT问题的多样性。 Oluaffunmilola 等人在进行目标预测的同时也跟踪了目标预测[50]。他们使用 Fairmot [54] 来检测边界框,然后堆叠预测网络,并生成联合学习架构(JLE)。 zhihong等人提取了每一帧的新特征来获取全局信息并积累一些用于覆盖处理的特征[51]。他们结合这两个特征来准确地检测行人。除了[52]之外,没有论文采取任何措施保留重要的边界框,使其在数据关联阶段不会被消除。经过测试,hong等人的概率应用了不可屏蔽抑制(NMS)来降低被重要边界去除的概率[53]。 jian 等人还使用 NMS 来减少检测器中的冗余边界框。他们通过比较特征并借助 iOU 重新识别边框来重新检测轨迹定位。最终结果是重新检测和重新识别跟踪器(JDI)的组合。
注意力模块
为了重新识别模糊目标,你需要注意。注意力是指作者只考虑感兴趣的目标。通过消除背景,它可以被记住很长时间,甚至在覆盖后也可以如此。注意力模块在MOT领域的应用如下表所示。
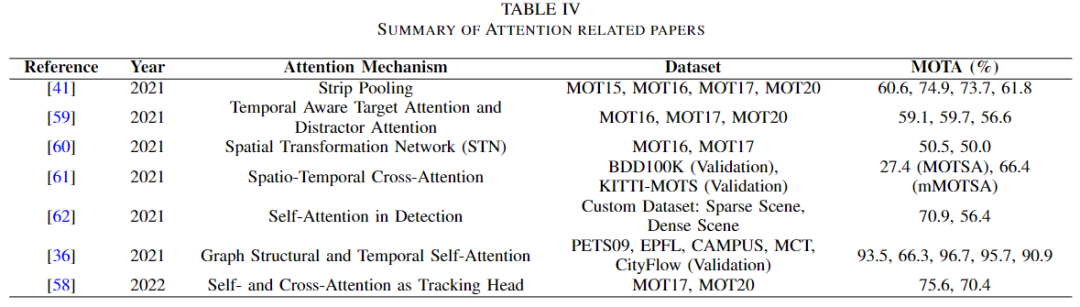
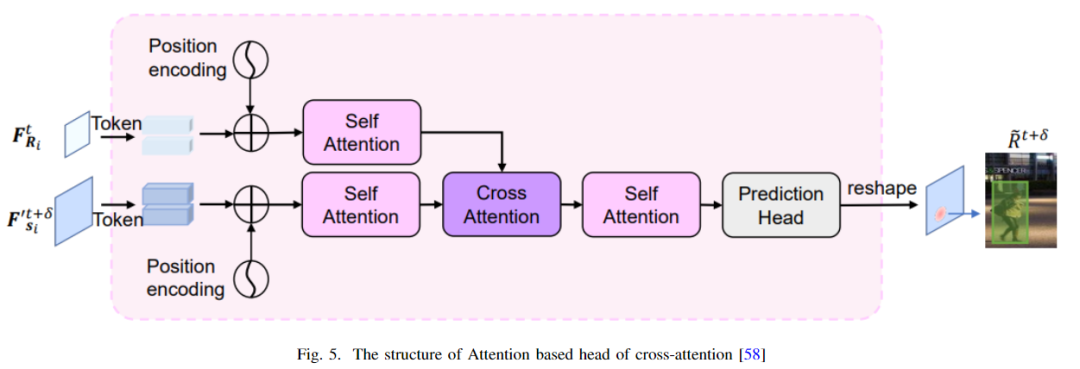
在[41]中,姚野等人引入了一个待关注模块来重新识别被背景阻挡的行人。这个模块实际上是一个池化层,包括MAX和Mean池化,可以更有效地提取行人的特征,这样当他们被遮挡时,模型不会忘记他们,可以进一步重新识别。宋等人希望利用数据关联中的目标定位信息,利用数据关联信息进行目标定位。为了将两者联系起来,他们使用了两个注意力模块,一个用于目标,另一个用于分散注意力。然后他们最终应用记忆聚合来增强注意力。 Tianyi等人提出了空间注意力机制[60],通过在外观模型中实现空间转换网络(STN)来迫使模型只能关注前景。另一方面,Lei等人首先提出了原型交叉关注模块(PCAM),从过去的帧中提取相关特征。然后他们使用原型交叉关注整个画面中前景和背景的比较特征[61]。 Huiyuan等人提出了一种自我护理机制来检测车辆[62]。这篇文章[36]还有一个应用于动态图的自注意力模块,以结合相机的内部和外部信息。 Jia Xu等人以轻量级的方式使用了交叉注意力和自注意力[58]。如下图所示,可以看到该架构的交叉注意力头。使用自理模块提取鲁棒性特征以减少背景覆盖。然后将数据传递给交叉关注模块来关联实例。
运动模型
锻炼是目标的必然属性。因此,该功能无论是测试还是关联都可以用在多目标跟踪领域。通过两帧之间的差异可以计算出目标的运动。根据这个衡量标准,您可以做出不同的决定,如下表所示。
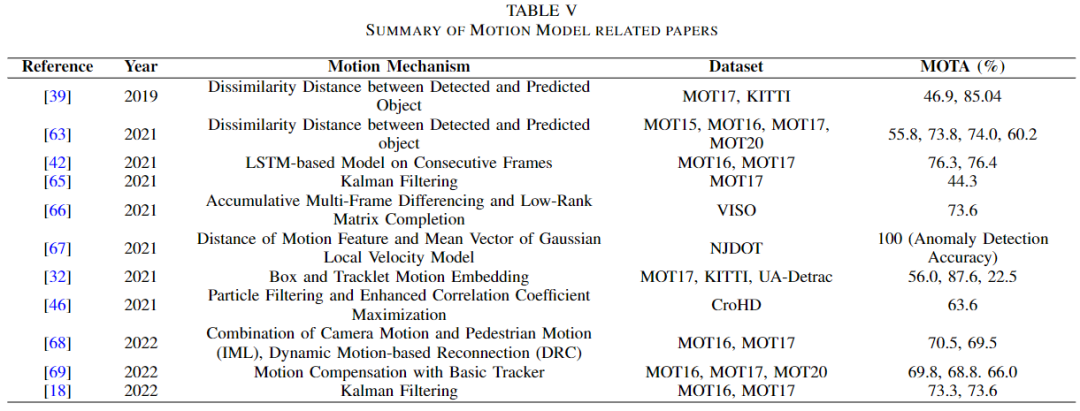
Hasith 等人、Oluaffunmilola 等人在 [39] 和 [63] 中使用运动来计算成本差异。根据实际位置和预测位置之间的差异计算运动。为了预测被阻挡的位置,毕升等人。使用基于 LSTM 的运动模型 [42]。 WenYuan等人将运动模型与深度亲和力网络(DAN)[64]相结合,通过消除无法定位目标的位置来优化数据关联[65]。人们等还通过累加连续卫星帧的多帧差异(AMFD)和低秩矩阵(LRMC)测量来计算运动[66],并形成运动模型基线(MMB)来检测和减少虚拟数量警察。 Essence Han等人将运动特性运用在车辆驾驶领域。他们通过比较运动特征和 GLV 模型来检测相关目标。高昂等人。建立一个局部全局运动(LGM)跟踪器,它可以找到运动的一致性并关联轨迹[32]。此外,RAMANA等人还使用运动模型来预测目标的运动,而不是数据关联。这些数据关联具有三个模块:综合运动定位(IML)、动态重连上下文(DRC)、3D积分图像(3DIIII)[46]。 2022年,Shoudong等人。通过提出运动感知跟踪器(MAT),运动模型被用来与运动预测和目标相关联。 zhibo等人提出了补偿跟踪器(CT),可以得到运动补偿模块的损失[69]。晓彤等人。使用运动模型来预测目标的边界框[18],如[67]中所示,但图像块的制作方式与 Transformer 章节中公开的类似。
原创第一个微信公众号【自动驾驶之心】:一个专注于自动驾驶和AI的社区()
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请联系本站,一经查实,本站将立刻删除。如若转载,请注明出处:http://www.ccyhlngy.com/html/tiyuwenda/9725.html

